











怎么删除背景音乐提取人声?使用简鹿人声分离工具提取



本教程将带您了解如何使用简鹿人声分离轻松完成这一任务。通过以下简单步骤,您可以快速掌握从安装软件到成功提取人声的全过程。无论您是初次尝试音频处理的新手,还是寻求更高效工作流程的专业人士,简鹿人声分离都将为您提供便捷的支持。
什么是简鹿人声分离?
简鹿人声分离是一款基于人工智能技术开发的音频处理工具,专门用于从复杂的音频环境中精准地提取人声。它支持 Windows 和 Mac 系统,界面直观友好,操作简便。该软件利用深度学习算法对音频信号进行分析,能够准确区分人声与背景音乐等其他声音元素,并提供高质量的人声输出。此外,简鹿人声分离还具备批量处理功能,使得同时处理多个文件变得轻而易举。
使用简鹿人声分离提取人声的步骤
步骤1:下载并安装简鹿人声分离
如果您还没有安装简鹿人声分离,请访问官方网站下载适用于您操作系统的最新版本。安装后打开简鹿人声分离后,您会看到一个简洁明了的界面。在主界面上找到“提取人声”选项,并点击进入。

步骤2:添加音频或视频文件
点击“添加文件”按钮,浏览并选择您想要处理的一个或多个音频或视频文件。简鹿人声分离支持多种格式,包括 MP3、WAV、FLAC、MP4 等。
步骤3:设置输出格式为 MP3
在底部的“输出格式”下拉菜单中选择“MP3”。这将确保所有选定的文件在处理后将以 MP3 格式保存,便于后续使用或分享。
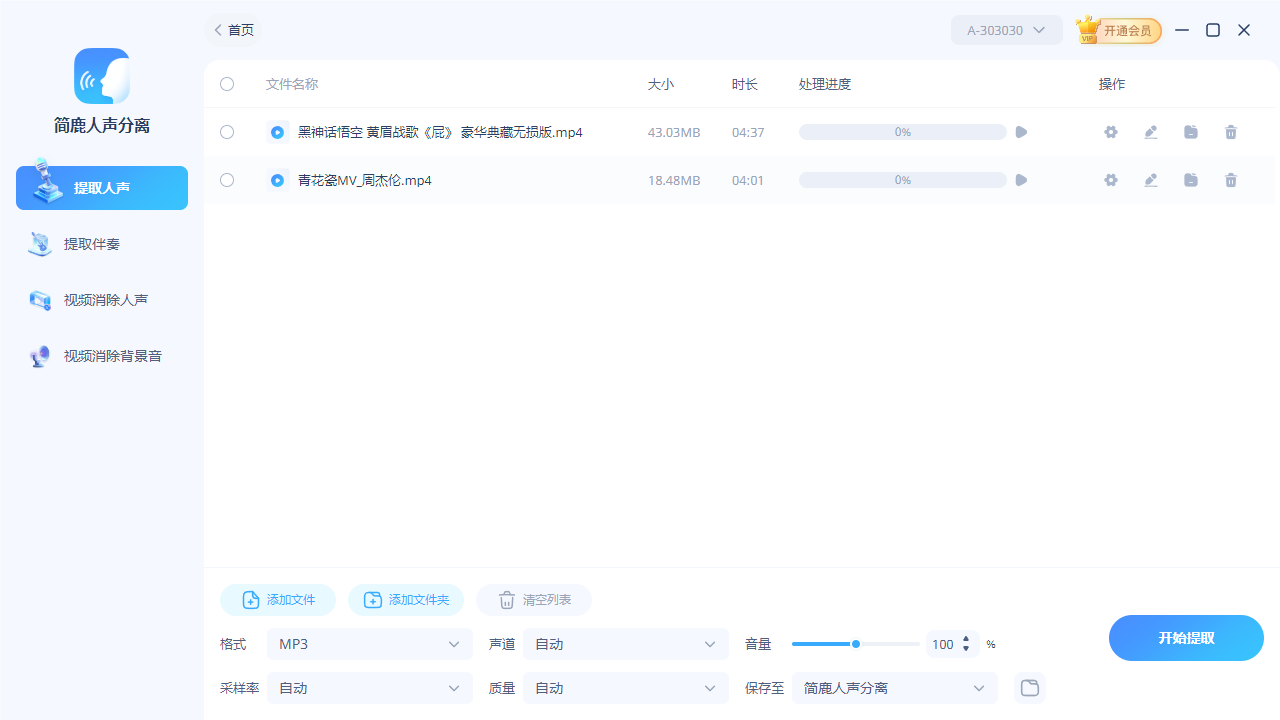
对于大多数情况,默认的输出参数已经足够好,但如果您有特殊需求,还可以进一步调整比特率、采样率等高级设置来优化音质与文件大小之间的平衡。如果没有特别要求,保持默认输出路径也是完全可以的。
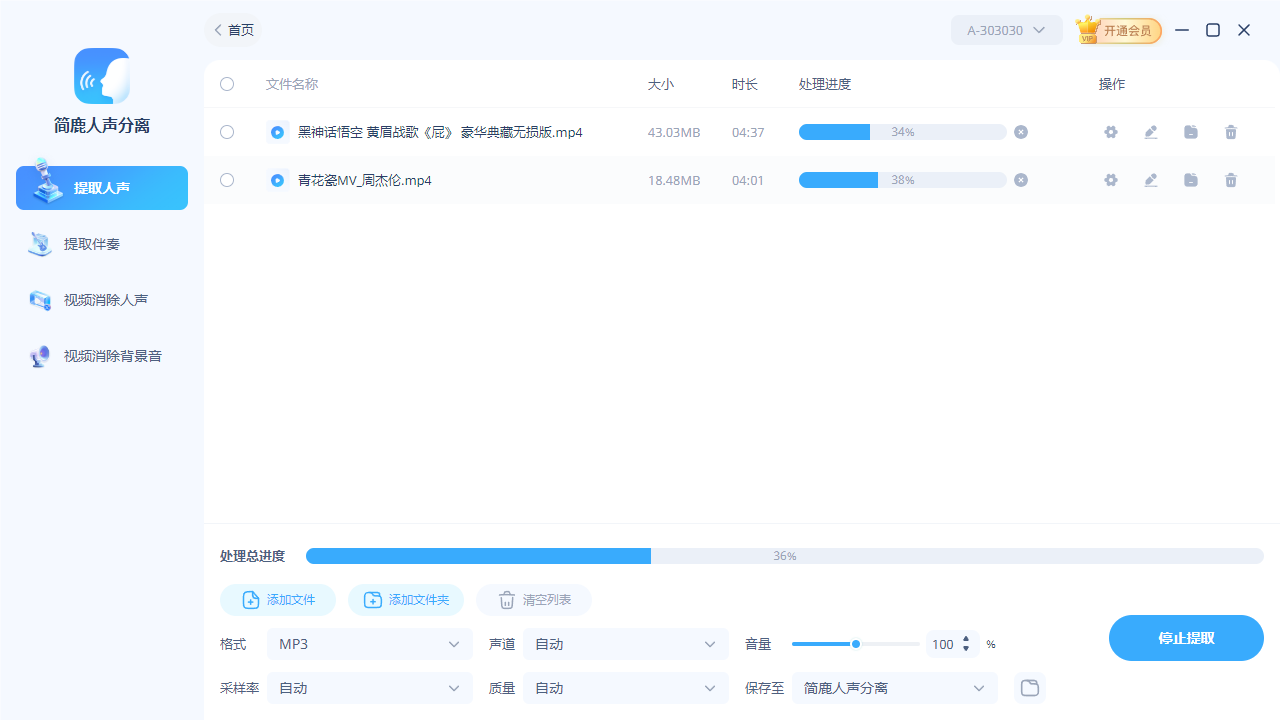
步骤4:开始提取
最后一步是点击“全部提取”按钮,简鹿人声分离将会立即开始处理您上传的所有文件。提取进度会在界面上实时显示,您可以随时查看任务状态。完成后,您就可以在指定的输出文件夹中找到新的、仅含人声的 MP3 文件了。
通过上述简单的步骤,您已经学会了如何使用简鹿人声分离从音频或视频文件中提取出清晰的人声。简鹿人声分离凭借其强大的 AI 算法和用户友好的界面,成为众多用户进行音频处理的理想选择。
小贴士
AI 算法的优势:简鹿人声分离所使用的 AI 技术不断进化,能够在复杂背景下有效提取人声,即使对于非专业用户也非常友好。
批量处理:如果需要处理大量文件,简鹿人声分离的批量处理功能可以帮助您节省大量时间和精力。
输出质量:根据实际用途调整输出音频的质量参数(如比特率),可以在保证音质的同时减少文件大小,方便存储和传输。














