











提取人声消除背景音乐教程来了,使用简鹿人声分离轻松搞定



在音频处理的需求中,提取人声(即消除背景音乐,保留干声)是一项非常实用的功能。无论是为了制作鬼畜素材、提取演讲录音,还是为了进行二次创作,我们都需要一款高效的工具。
目前网络上虽然有许多在线服务,但往往伴随着上传速度慢、隐私泄露风险或音质压缩等问题。今天,我们将使用一款支持本地处理的工具 —— 简鹿人声分离,为大家带来一份详细的提取人声教程。
为什么选择简鹿人声分离?
在开始之前,简要介绍一下这款工具的核心优势:
本地处理,隐私安全:这是该软件最大的亮点。所有的音频处理都在你的电脑本地完成,无需将文件上传到云端服务器,完全不用担心隐私泄露问题。
跨平台支持:软件同时支持 Windows 和 Mac 操作系统,界面设计统一,操作逻辑简单。
AI 智能分离:利用 AI 算法,能够较为精准地识别并分离人声与背景音乐,保留清晰的人声轨道。
轻松提取人声详细操作步骤
请按照以下步骤,只需几分钟即可提取出纯净的人声。
第一步:选择功能模式
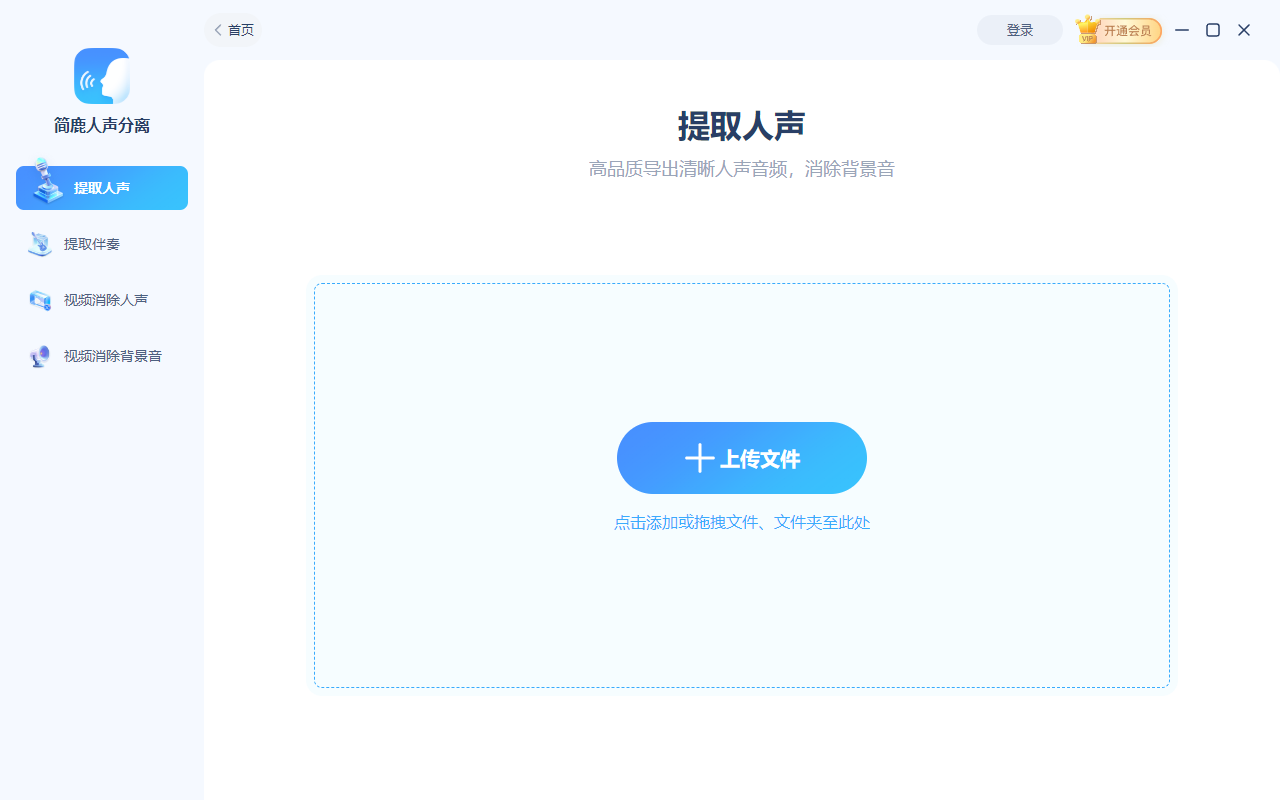
打开软件,你会看到简洁的主界面。界面上提供了多种功能选项,包括“提取伴奏”、“视频消除人声”等。我们需要点击【提取人声】按钮,进入人声提取的专属工作区。

第二步:导入素材
进入功能页面后,点击【+ 上传文件】按钮。在弹出的文件选择窗口中,找到并选中你想要处理的音频或视频文件。该软件支持批量处理,你也可以一次性添加多个文件。
第三步:设置输出参数
文件添加成功后,我们需要简单设置一下导出格式。
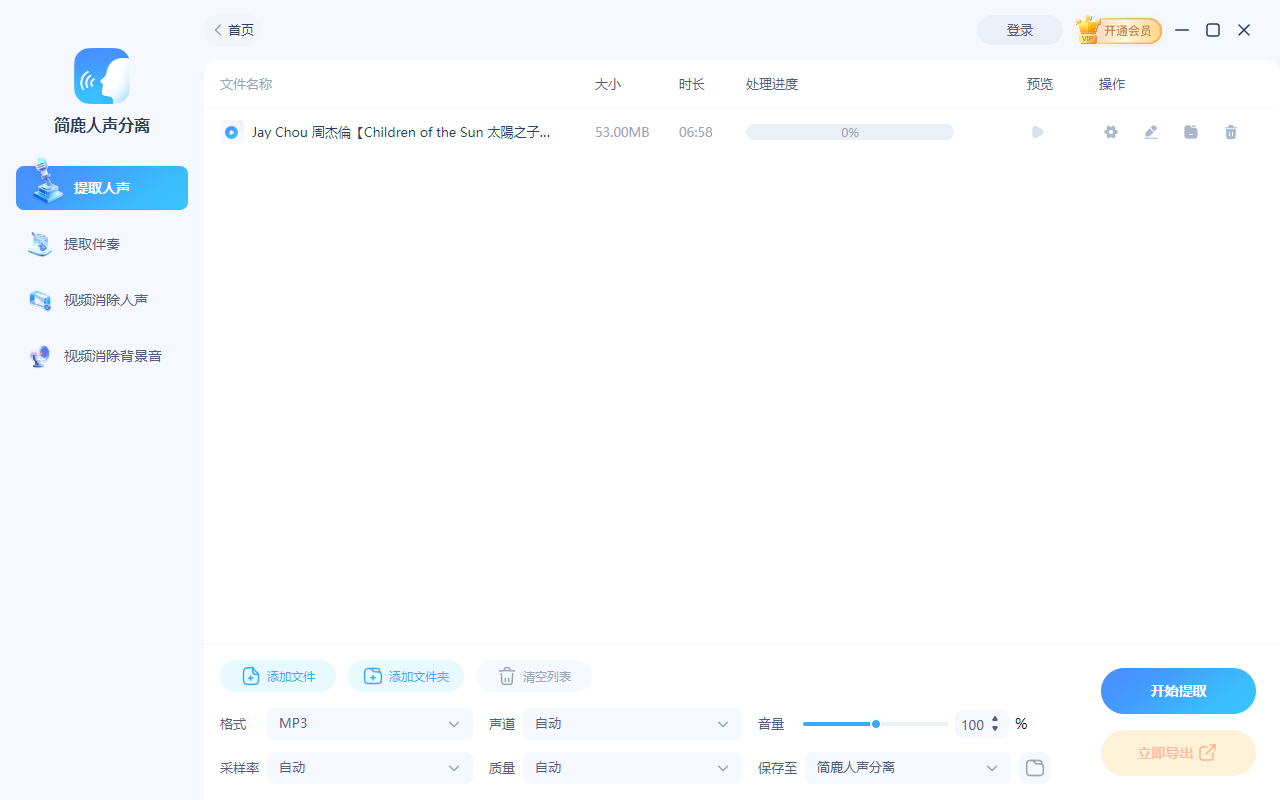
默认情况下,软件可能预设了某种格式。如果你希望得到通用的音频文件,请在设置区域将格式选择为 MP3。当然,如果你追求更高音质,也可以选择 WAV 或 FLAC。采样率、声道等参数通常保持“自动”即可,软件会根据源文件自动匹配最佳设置。
第四步:开始提取
确认所有设置无误后,点击界面下方的【开始提取】按钮。软件将立即调用本地算力开始分析音频。由于是本地处理,速度取决于你电脑的性能,通常只需几分钟甚至更短时间。
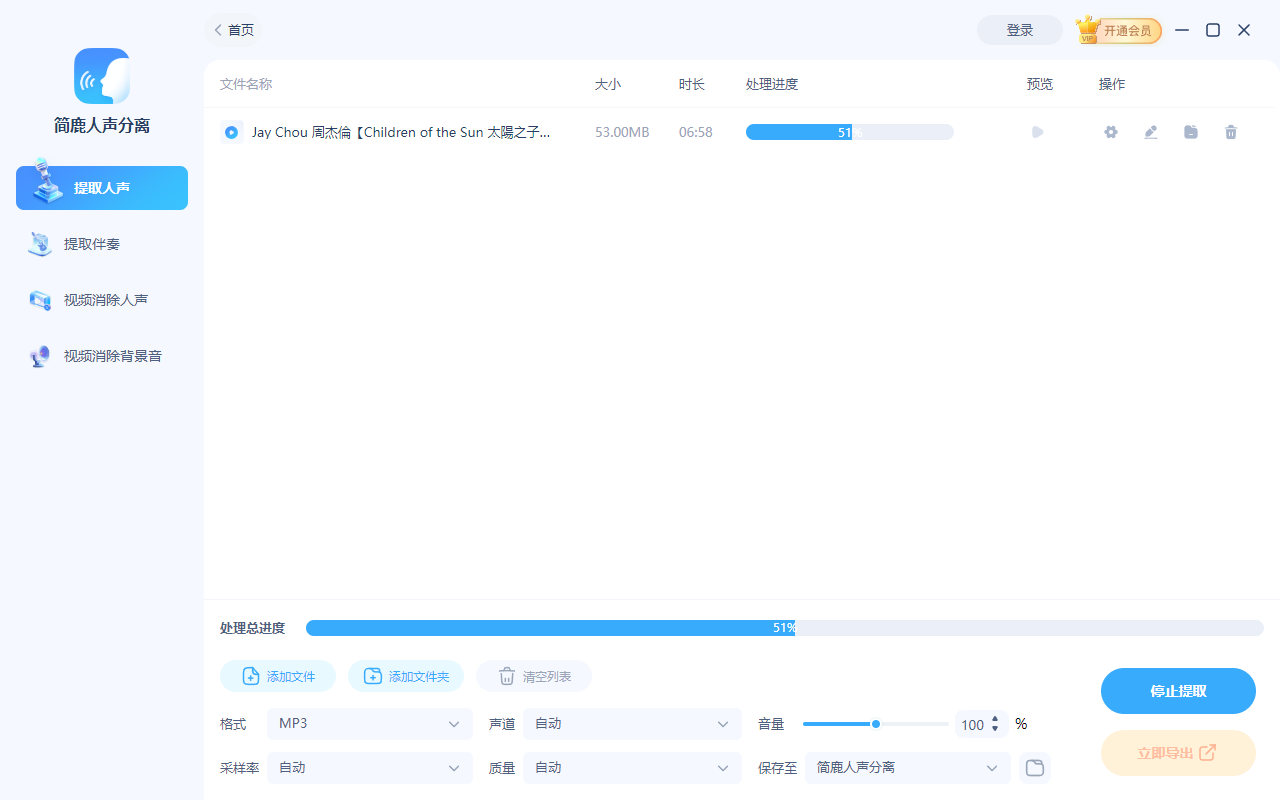
第五步:获取结果
当进度条显示 100% 处理完成后,你可以点击“打开文件夹”或在输出目录中找到生成的文件。此时,你将获得一个去除了背景音乐、只保留清晰人声的音频文件。
通过以上简单的四个步骤,我们就利用简鹿人声分离完成了人声提取工作。相比于复杂的音频编辑软件(如 Audacity 或 Adobe Audition),这款工具极大地降低了操作门槛,让没有专业背景的用户也能轻松上手。














