











OpenAI 正式发布 GPT-5.5 Instant,ChatGPT 迎来全新默认模型



OpenAI 已开始部署 GPT-5.5 Instant,这款新的基础模型将全面取代 GPT-5.3 Instant,服务于所有用户。官方宣称,新模型在减少“幻觉”和事实错误方面表现显著,回答更加简练精准,且对用户上下文的理解能力得到了大幅提升。

OpenAI 正逐步将 GPT-5.5 Instant 设为 ChatGPT 的默认模型。根据公司内部测试数据,在医学、法律和金融领域的提示词测试中,新模型的幻觉率比 GPT-5.3 Instant 降低了 52.5%,在用户曾反馈存在事实错误的复杂对话中,不准确陈述减少了 37.3%。在基准测试方面,GPT-5.5 Instant 在 AIME 2025(数学竞赛)中得分为 81.2%(前代为 65.4%),在 MMMU-Pro(多模态理解)中得分为 76.0%(前代为 69.2%)。
GPT-5.5 Instant 为 ChatGPT 带来了什么改变?
作为 ChatGPT 的基础模型,GPT-5.5 Instant 每天为数亿用户提供服务,涵盖快速问答、文本辅助、数据分析、编程支持、图像解析及日常任务处理。在 API 中,该模型的标识符为 chat-latest。
OpenAI 此次升级主要聚焦于三个方向:
事实准确性:大幅减少捏造事实的情况。
回答简练度:去除了冗余的追问和过度的格式排版,减少了装饰性表情符号的使用,力求在不丢失核心内容的前提下更加简洁。
上下文利用:更智能地调用用户历史数据。
注:幻觉是指语言模型将虚构的事实(如不存在的论文、错误的引用、错误的数值)当作真实信息输出的现象。
OpenAI 公布的数据显示,除了 OmniDocBench(该测试分数越低越好)外,新模型在所有测试中均优于前代。
数学能力:差距最明显的是 AIME 2025,新模型领先了 15.8 个百分点。
医疗专业度:在面向专业用户的临床版 HealthBench 测试中,新模型在百分制下领先了 5.5 分。OpenAI 特别强调了这一点,因为医疗咨询是 ChatGPT 最高频的使用场景之一。
公司同时声明,这些数据来自内部测试,并未随发布一同公布与竞争对手模型的第三方对比结果。
GPT-5.5 Instant 极大地扩展了对用户上下文的处理能力,包括过往聊天记录、上传的文件以及关联的 Gmail 邮箱。OpenAI 表示,开发团队优化了模型判断“何时需要个性化”的能力,并加快了在聊天历史中搜索相关片段的速率——这意味着用户不再需要反复重复相同的信息。
部署计划:
首批:Plus 和 Pro 订阅用户(Web 端)。
后续:移动端应用将在稍后支持。
全面覆盖:未来几周内,Free、Go、Business 和 Enterprise 套餐用户也将获得该功能。
伴随新模型,OpenAI 还在所有 ChatGPT 模型中推出了“记忆来源”功能。当回答包含个性化内容时,界面现在会明确显示使用了哪些上下文:是保存的“记忆”,还是过往的聊天记录。用户可以删除或修正任何不需要或过时的条目。
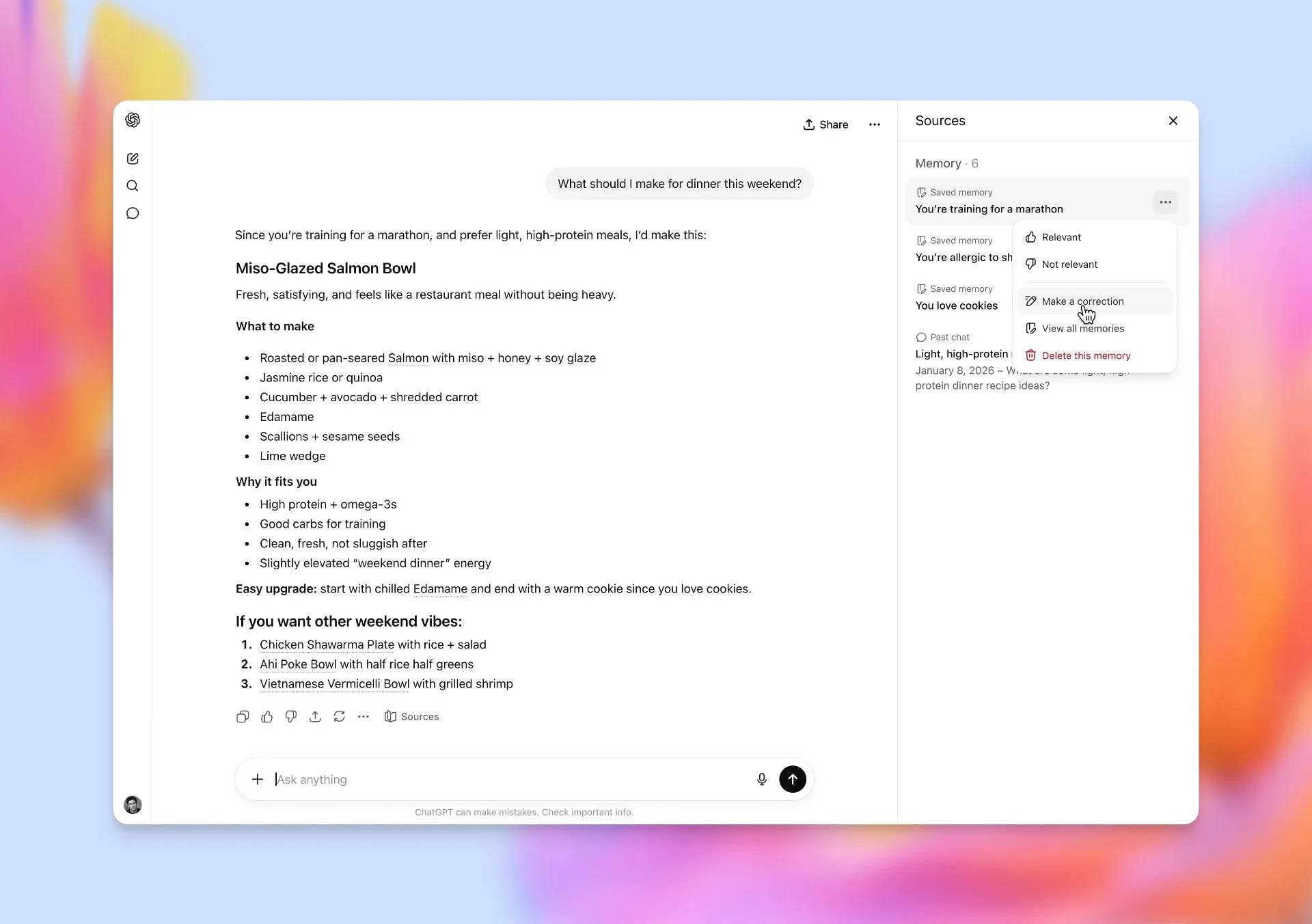
OpenAI 特别强调:在共享聊天(多人协作)时,对方无法看到你的记忆来源。用户可以在设置中编辑保存的记忆,而“临时聊天”模式则完全不会读取或更新保存的上下文。
记忆来源:这是 ChatGPT 界面的一项功能,用于展示影响个性化回答的保存记忆和过往聊天。根据官方说明,来源中可能仅显示最相关的因素,而非全部。
GPT-5.5 Instant 的部署已于今日面向所有 ChatGPT 用户及 API 开启。付费订阅用户仍可保留 GPT-5.3 Instant 三个月(需在模型配置设置中选择),之后该旧模型将停止服务。
系统卡片中还指出了一个关键细节:GPT-5.5 Instant 是 Instant 系列中首个在网络安全和生物领域被 OpenAI 评定为“高能力”级别的模型。这意味着该模型具备显著增强攻击者能力的潜力,因此需要像更强大的“Thinking”系列模型一样,在部署时采取加强的安全防护措施。
此次更新改变了 ChatGPT 的基础体验,而非推出独立的溢价产品。这意味着在事实准确性、回答长度和上下文处理方面的改进,将惠及包括免费用户在内的最广泛受众。ChatGPT 正继续从一个通用的聊天机器人,进化为一个基于用户过往记录、文件和连接服务,并在用户控制下提供支持的智能助手。














