











如何提取音频中的纯人声?使用简鹿人声分离工具轻松搞定



在音乐制作、配音剪辑、内容创作等场景中,我们常常需要从一段包含背景音乐或环境音的音频中提取出“干净”的人声。然而,对于大多数非专业用户来说,手动分离人声不仅技术门槛高,而且效果难以保证。
随着人工智能技术的发展,如今已有不少简单易用的工具可以帮助我们一键完成这项任务。本文将为大家介绍一款高效、免费且支持本地运行的AI人声分离软件 —— 简鹿人声分离,并手把手教你如何用它提取音频中的纯人声。
什么是简鹿人声分离?
简鹿人声分离是一款基于先进AI模型算法开发的本地音频处理工具,无需联网即可运行,保护你的隐私与数据安全。它同时支持 Windows 和 macOS 系统,界面简洁,操作直观,非常适合普通用户使用。
该软件主要提供以下四大功能:
提取人声(保留人声,去除伴奏/背景音)
提取伴奏(保留背景音乐,去除人声)
视频消除人声(保留视频画面与背景音,移除人声)
视频消除背景音(保留人声与画面,去除环境杂音)
今天,我们将重点讲解如何使用它来提取音频中的纯人声。
一键提取音频中的纯人声操作步骤
第一步:下载并安装软件
前往简鹿人声分离的官方网站(或可信渠道),根据你的操作系统下载对应的 Windows 或 macOS 版本,安装后打开软件。
第二步:选择“提取人声”功能
启动软件后,在主界面中点击 “提取人声” 功能模块。该模式会自动识别人声部分,并将其从原始音频中分离出来。

第三步:上传你的音频或视频文件
点击 “上传文件” 按钮,选择你想要处理的音频文件(如 MP3、WAV、M4A 等)或视频文件(如 MP4、MOV 等)。支持批量添加,方便一次性处理多个素材。
小提示:如果你只有视频,软件也会自动提取其中的音频进行处理,最终输出纯人声音频文件。
第四步:设置输出格式(推荐 WAV)
在输出设置中,建议将输出格式选择为 WAV。WAV 是无损音频格式,能最大程度保留人声的清晰度和细节,特别适合后续用于配音、剪辑或专业处理。

当然,如果你对文件体积有要求,也可以选择 MP3 等压缩格式,但音质会略有损失。
第五步:点击“全部提取”开始处理
确认设置无误后,点击 “全部提取” 按钮。软件将利用本地AI模型自动分析并分离人声,处理速度取决于文件长度和电脑性能。
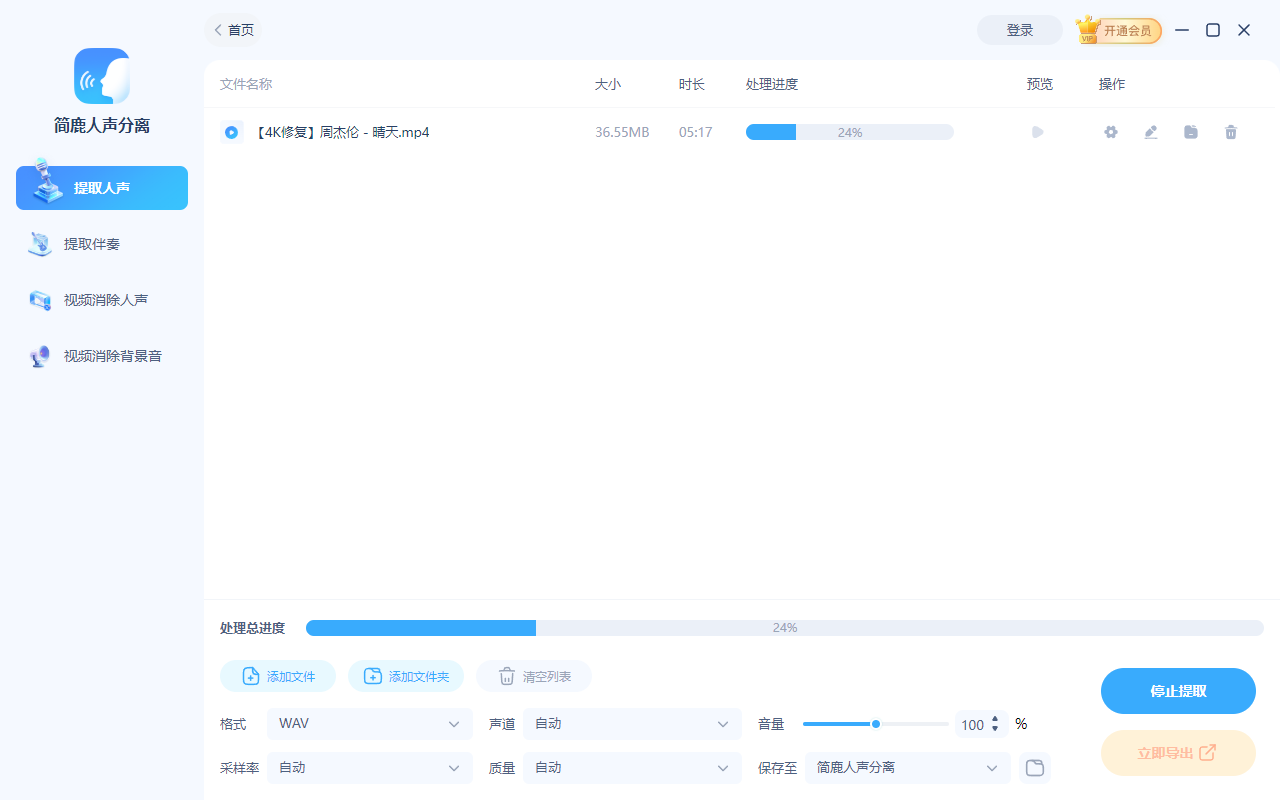
处理完成后,你可以在指定输出文件夹中找到提取好的纯人声音频文件。
提升提取效果的小技巧
虽然AI工具非常强大,但输入素材的质量直接决定输出效果。为了获得最佳的人声分离结果,请注意以下几点:
尽量使用高质量原始音频(如16bit/44.1kHz以上采样率);
避免使用严重压缩、失真或混响过重的音频;
若原音频中人声与伴奏频率重叠严重(如某些流行歌曲),AI可能无法做到100%完美分离,但日常使用已足够清晰。
借助 简鹿人声分离 这类AI驱动的本地工具,即使没有专业音频知识,普通用户也能轻松提取出干净的人声。无论是做短视频配音、翻唱练习,还是语音转文字前的预处理,它都能大幅简化工作流程。














