











Google Translate 迎来重大升级,Gemini 驱动实时语音翻译新体验



谷歌正在为其 Gemini 音频模型推出一次重大更新,为谷歌翻译(Google Translate)应用带来强大的实时语音到语音翻译功能。此次升级采用了改进后的 Gemini 2.5 Flash Native Audio 模型,专为处理复杂的语音交互而设计。
这项全新的实时语音翻译功能专为耳机用户打造,让你能实时听到周围世界被翻译成你所理解的语言。这一测试版功能现已在谷歌翻译应用中上线。无论你是在旅行途中,还是需要跨越语言障碍进行沟通,这项功能都可能彻底改变你与母语不同的人交流的方式。

该功能分为两种模式。第一种是“持续聆听”模式,非常适合听讲座或参与多人对话等场景。人工智能可同时识别多种语言,并将它们全部转换为你设定的目标语言。你只需戴上耳机,就能直接听到被翻译后的内容。第二种是“双向对话”模式。
该模式支持两种特定语言之间的实时互译,并能根据说话人自动切换翻译语言。例如,如果你说英语,而对面的人说印地语,你将在耳机中即时听到英语翻译;当你回应时,你的手机会立即将你说的话翻译成印地语并播放出来。
让这项功能真正脱颖而出的细节在于“风格迁移”技术。它能让用户听到人类语音中的细微差别 —— 系统会模仿说话者的真实声音,匹配其语速和语调,使翻译听起来不再机械生硬。此外,系统还具备强大的降噪能力,即使身处嘈杂的户外环境,你也能轻松顺畅地进行对话。
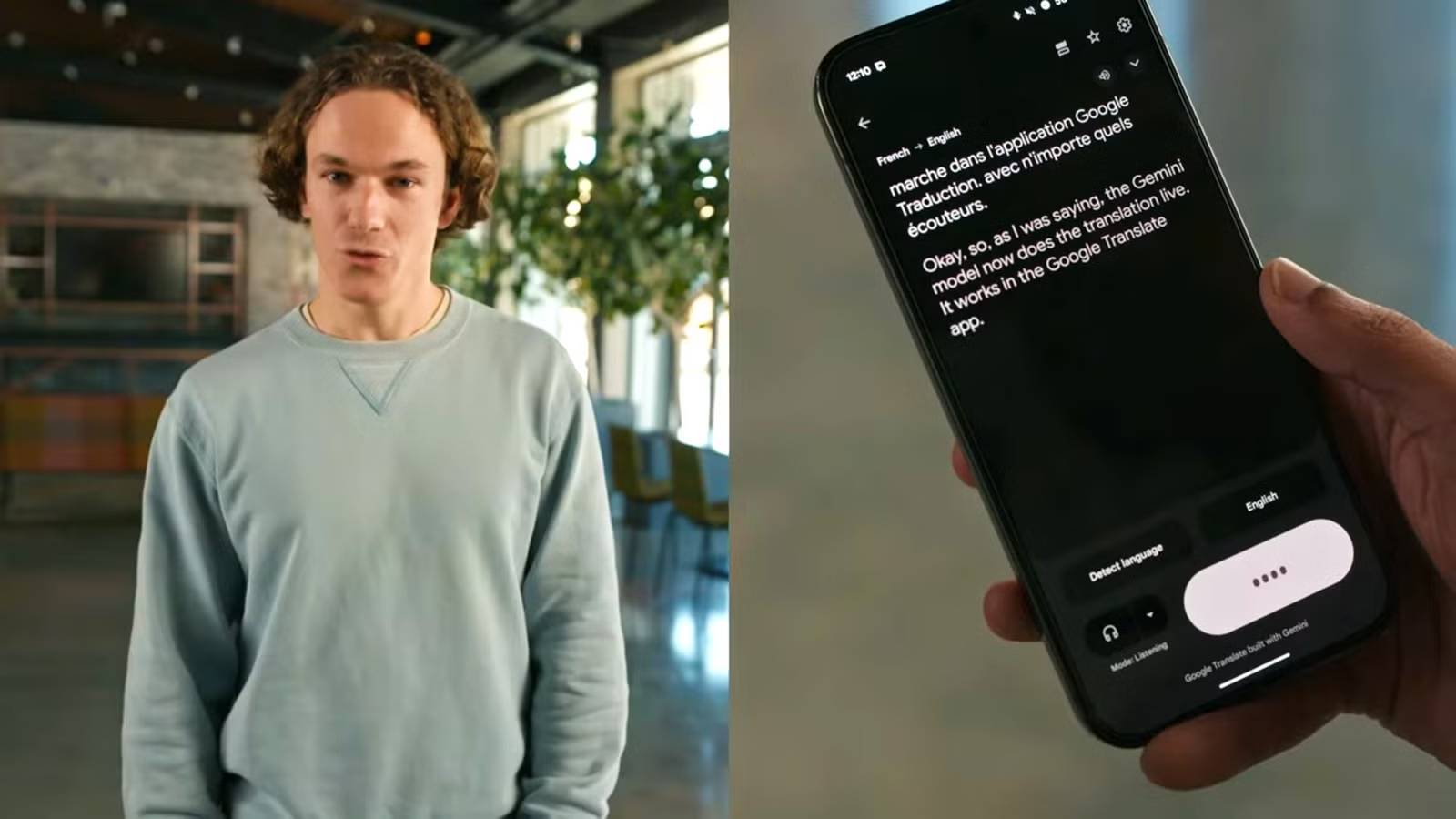
翻译覆盖范围极为广泛,支持70多种语言、超过2,000种语言组合。如此广泛的语种支持得益于 Gemini 强大的音频处理能力与其庞大的语言数据库的结合。
另一项关键特性是多语言输入与自动检测功能。系统可在单次会话中同时识别多种语言,你无需手动调整设置,甚至不需要知道对方说的是哪种语言 —— 应用会自动识别并立即开始翻译。
这一切背后的核心是全新升级的 Gemini 2.5 Flash Native Audio 模型,该模型同时也为谷歌多个产品中的实时语音助手提供支持。谷歌在三个关键技术领域对该模型进行了优化,从而为用户带来更迅捷流畅的体验。
首先,模型现在具备更精准的函数调用能力,这意味着当系统需要连接外部工具时更加可靠。例如,在你说话的同时,它能实时获取最新数据,而不会中断或打断对话流程。谷歌表示,新版本对开发者指令的遵循率已达到 90%,高于此前版本的 84%。
其次,对话本身也变得更加连贯。模型能够记住你在聊天早期说过的内容,从而更好地保持话题一致性,避免出现支离破碎的对话体验。可以说,这种多轮对话质量的提升,正是任何语音助手实现稳定性的关键所在。
这些改进不仅限于谷歌翻译应用。新的 Gemini 2.5 Flash Native Audio 模型正逐步集成到谷歌的多个产品中,包括 Google AI Studio、Vertex AI、Gemini Live 以及 Search Live。用户未来在使用 Gemini Live 进行头脑风暴,或在Search Live中获取实时帮助时,都将获得更高效、更智能的体验。
如果你想亲自体验这项实时翻译功能,测试版即日起已在谷歌翻译应用中推出。只需将耳机连接到设备,点击“实时翻译”即可开始使用。目前该功能仅在美国、墨西哥和印度的 Android 设备上可用,iOS 版本及更多地区的支持将很快推出。














