











重磅升级!OpenAI 推出 GPT-5.2 以及 API 定价公布



OpenAI 正式推出 GPT-5.2 模型,聚焦于智能体(Agent)应用场景。该模型在 SWE-Bench Pro 基准测试中的表现提升至 55.6%,工具调用准确率高达 98.7%。API 定价已更新:输入令牌每百万 1.75 美元,输出令牌每百万 14 美元,并对缓存输入令牌提供高达 90% 的折扣。

OpenAI 公司正式宣布扩展其前沿(Frontier)大模型产品线。新版本 GPT-5.2 被定位为专用于解决复杂专业任务的工具。该模型的核心发展方向包括构建智能体工作流(agent pipelines)、多模态数据处理,以及支持长时间运行、依赖超长上下文的操作。
工程任务与代码能力进步
在软件开发领域,GPT-5.2 展现出显著性能提升。根据 SWE-Bench Pro(业内公认最严苛的模拟真实开发场景基准之一)的测试结果,GPT-5.2 Thinking 版本成功解决了 55.6% 的任务;相比之下,前代 GPT-5.1 的成绩为 50.8%。在简化版测试 SWE-Bench Verified 中,其成功率更是达到 80%。
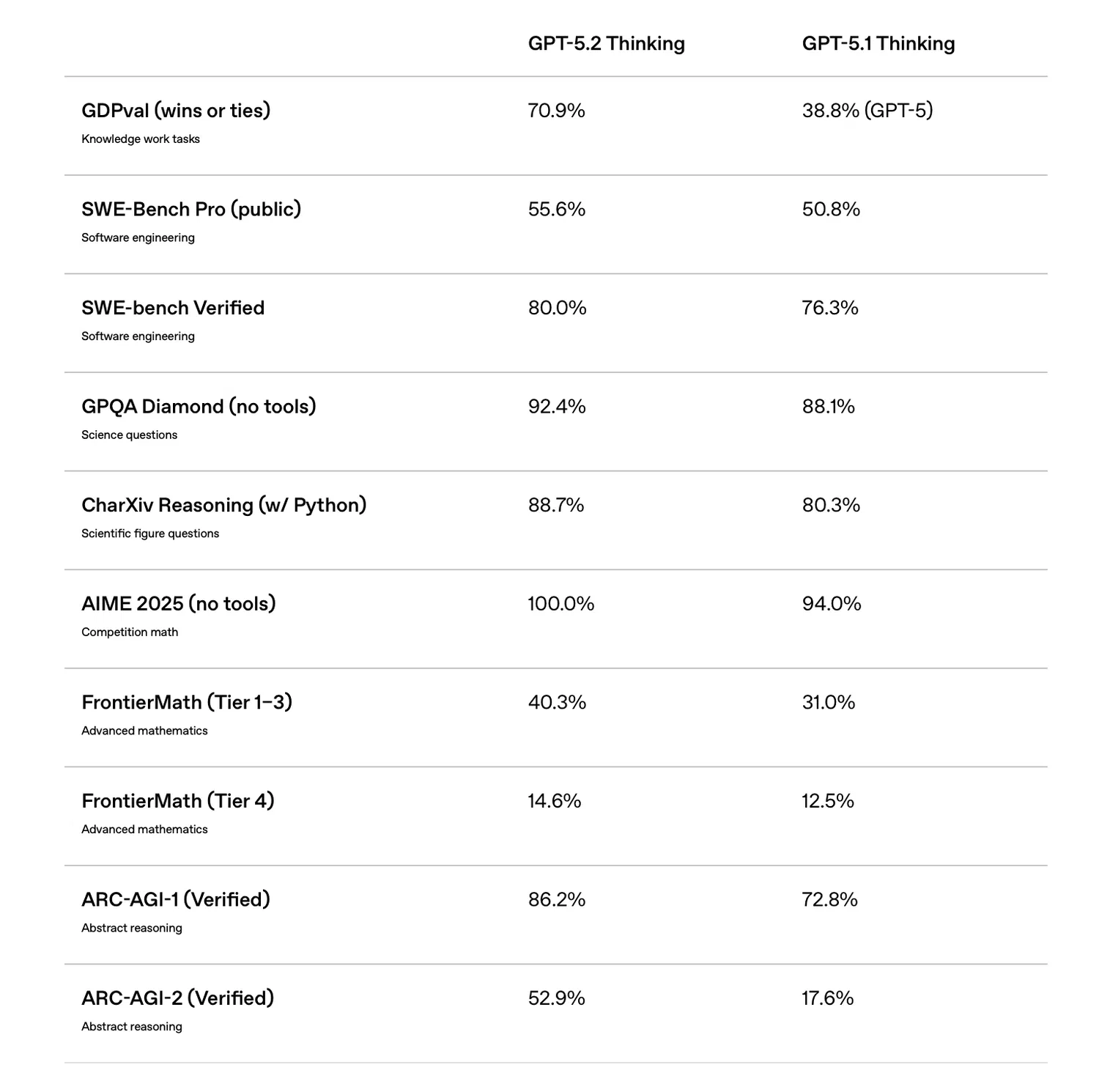
这一进步表明,人工修补补丁的需求正在减少,模型在处理大型代码仓库时的稳定性也显著增强。GPT-5.2 正从辅助编程助手逐步演变为能够近乎自主修复漏洞、实现新功能的完整开发工具。
早期测试用户特别指出,该模型在前端开发方面取得重大进展。仅凭一个详细提示(prompt),系统即可生成复杂的用户界面,包括非传统的 3D 元素和 UI 组件。如今,GPT-5.2 越来越被视为一种完整的全栈(full-stack)解决方案,而不再仅仅是代码生成器。
上下文管理与数据处理能力
针对长对话中信息丢失的问题,GPT-5.2 提供了有效的技术方案。其上下文窗口现已支持高达 256,000 个令牌。在 MRCRv2 测试中,即使目标信息被淹没在数十万个其他令牌之中,模型仍能近乎无误地提取关键内容。
在实际应用中,这意味着用户可直接上传多页合同、企业财报、多文件项目或聊天记录档案,而不会丢失逻辑连贯性。模型在整个会话过程中始终保持回答的一致性。此外,系统还新增了“compact 模式”,使模型能够在标准上下文窗口之外继续“思考”和运行,这对实现长时间智能体任务至关重要。
智能体场景可靠性(工具调用)
在外部工具调用的可靠性方面,GPT-5.2 实现了显著飞跃。在 Tau2-bench Telecom 基准测试中,新模型的工具调用成功率高达 98.7%。值得注意的是,即便在启用快速推理模式(reasoning.effort="none")的情况下,其准确率依然大幅提升。
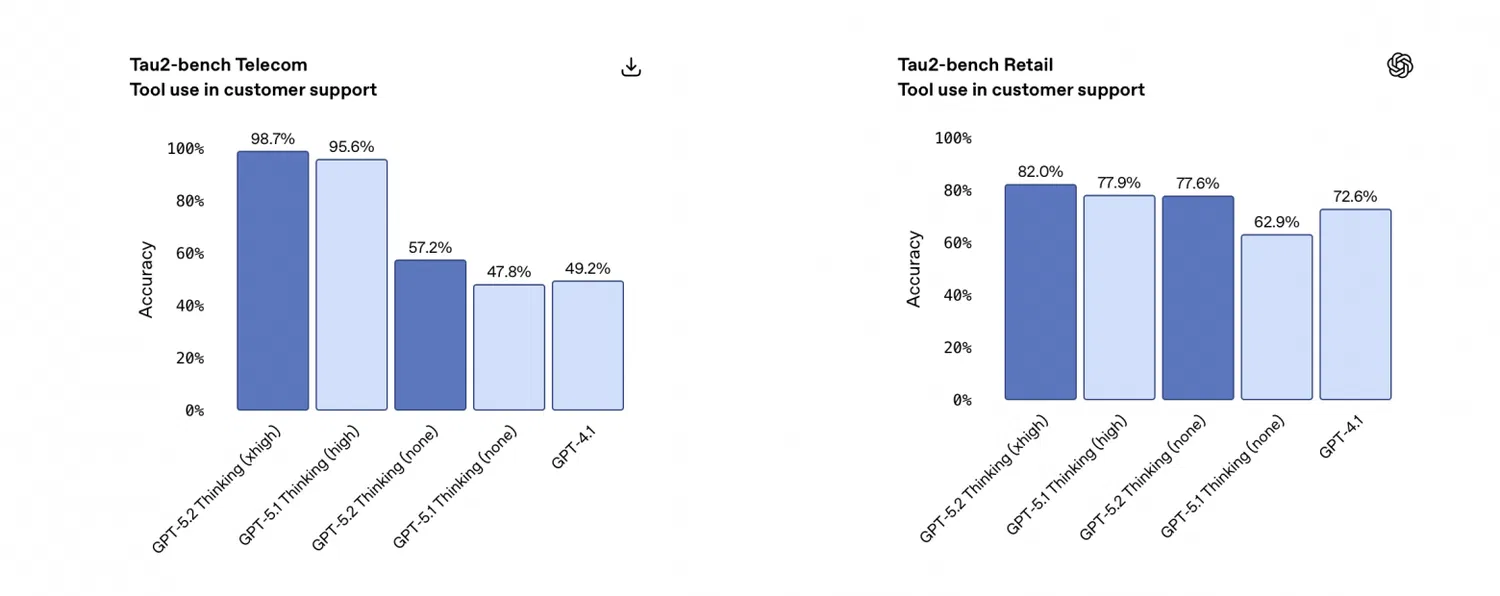
已有若干企业客户表示,他们正借此优化自身系统架构:从原先依赖多个专用小型智能体,转向部署单一“超级智能体”,由其统一调度超过 20 种工具。
视觉分析能力与幻觉减少
开发团队进一步增强了系统的多模态能力。GPT-5.2 在解读技术图纸、仪表盘、图表及用户界面等视觉内容方面更加准确。在 GUI 识别与分析任务中的错误率几乎减半。对于需要读取图表并解释流程的任务,模型表现得更为细致严谨。
此外,事实性错误(即所谓“幻觉”)的发生率降低了约三分之一。这一改进对于将大模型应用于商业分析、文档摘要生成及商务沟通等场景具有关键意义。
定价策略与 API 接入
GPT-5.2 已集成至 ChatGPT 界面,面向 Plus、Pro、Business 和 Enterprise 订阅用户提供服务。开发者可通过 API 使用该模型,对应标识符为 gpt-5.2 和 gpt-5.2-chat-latest。性能最强的版本命名为 gpt-5.2-pro。
相较于 GPT-5.1,新版 API 定价有所上调:
输入令牌:每百万令牌 1.75 美元
输出令牌:每百万令牌 14 美元
缓存输入令牌:享受 90% 折扣
OpenAI 强调,尽管单位价格有所上涨,但企业用户的总体成本可能反而下降。这是因为 GPT-5.2 能以更少的冗余令牌和迭代次数完成相同任务 —— 它执行效率更高,且所需澄清和修正更少。














