











小米 MiMo-V2-Flash 媲美 GPT-5 与 Claude 4.5 Sonnet 的开源 AI 模型



简鹿办公了解到,目前小米公司正式发布了当前最先进的大语言模型 —— MiMo-V2-Flash。该模型是小米全面推进基础大模型战略的重要组成部分,设计重点聚焦于高推理速度与架构效率,同时保留强大的逻辑推理与代码生成能力。
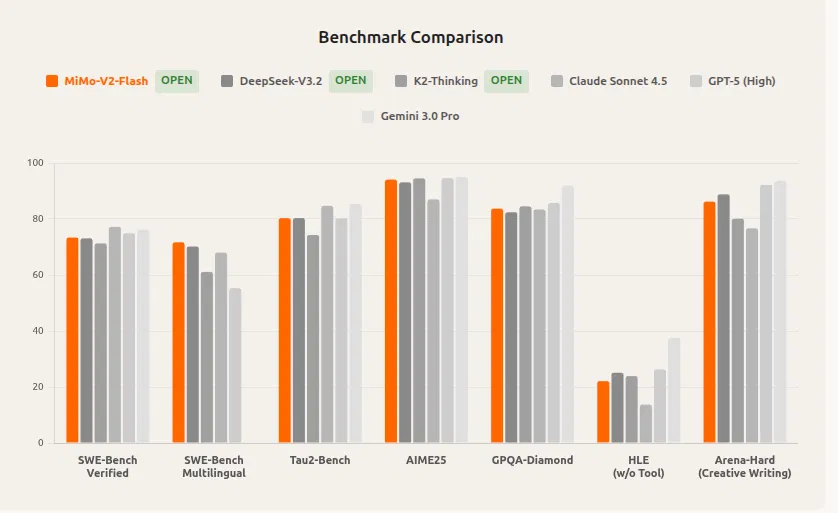
小米将 MiMo-V2-Flash 定位为市场上主流模型的直接竞争者,包括 DeepSeek V3.2 和 Claude 4.5 Sonnet。
面向智能体应用的架构与技术规格
MiMo-V2-Flash 基于 Mixture-of-Experts(MoE)架构,总参数量达 3090 亿,其中每次推理激活约 150 亿参数。该模型专为 AI 智能体场景和多轮复杂对话 而优化,尤其强调输出速度。
其注意力机制采用 1:5 混合注意力结构,结合了全局注意力(Global Attention)与滑动窗口注意力(Sliding Window Attention, SWA),窗口大小为 128 个 token。模型原生支持 32,000 个 token 的上下文长度,并在训练阶段实现了对 最长 256,000 个 token 上下文的处理能力。这种设计使其在长上下文任务扩展中表现出色。
据开发者称,MiMo-V2-Flash 的响应速度优于 DeepSeek、Claude 等主流模型,同时显著降低了运营成本。
基准测试表现与定价策略
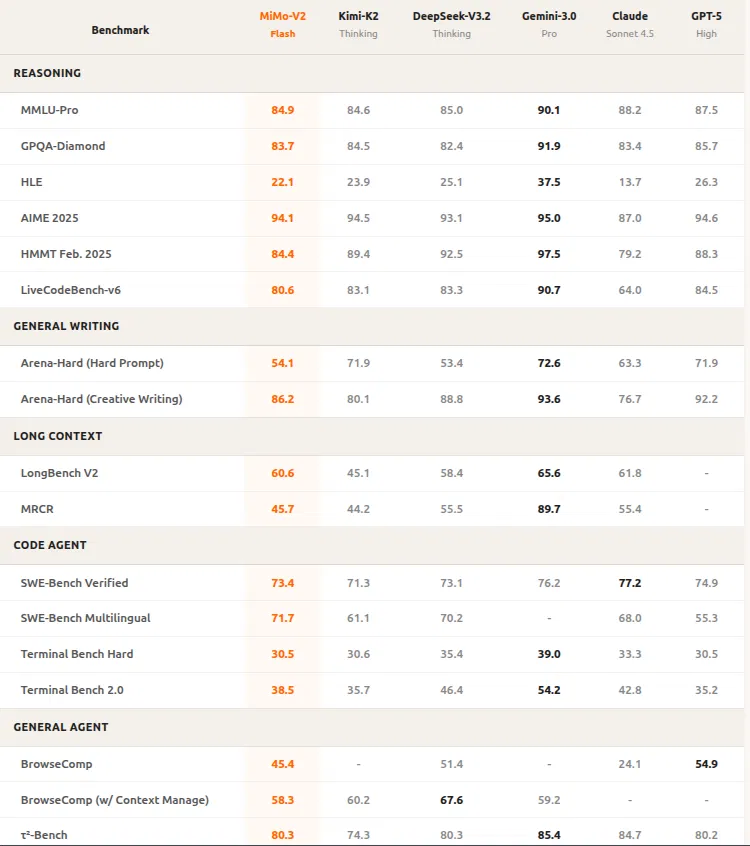
MiMo-V2-Flash 在多个维度均达到顶尖水平。在逻辑推理任务(如 AIME 2025 和 GPQA-Diamond 测试)中,它稳居开源模型前两名。
在软件工程专项评测(如 SWE-Bench Verified 和 SWE-Bench Multilingual)中,该模型不仅大幅领先其他开源方案,性能更可与 GPT-5 和 Claude 4.5 Sonnet 相媲美。
小米为 MiMo-V2-Flash 的 API 定价极具竞争力:
输入 token:0.1 美元 / 百万
输出 token:0.3 美元 / 百万
目前,API 正在限时免费开放。模型推理速度高达 150 token/秒,其推理成本仅为 Claude 运营成本的 2.5%。
技术创新与训练方法
模型的核心创新之一是采用了 多令牌预测(Multi-Token Prediction, MTP)技术。该技术可并行生成多个 token,并在输出前进行验证,从而在不增加内存或注意力机制负担的前提下,显著提升解码吞吐量。通过三层 MTP 结构,推理速度相比传统方法提升 2.0–2.6 倍。
此外,小米还推出了一种新型微调方法 —— 多教师在线策略蒸馏(Multi-Teacher Online Policy Distillation, MOPD)。该方法利用多个“教师模型”通过 token 级别的奖励信号指导学生模型训练。借助 MOPD,小米仅用不到传统强化学习(RL)训练流程 1/50 的资源,就实现了卓越的模型性能。该系统还支持灵活接入新教师模型,为模型的持续自我进化提供了可能。
模型访问方式
小米已上线 MiMo Studio 网页交互平台(地址:aistudio.xiaomimimo.com),用户可通过浏览器直接体验 MiMo-V2-Flash。
注意:访问该平台可能需要 中国大陆 IP 地址 及 小米账户。
平台支持联网搜索、智能体任务执行和代码生成,并提供两种模式切换:
快速响应模式:适用于日常问答;
深度思考模式:用于解决复杂逻辑问题。
开源许可
MiMo-V2-Flash 是一个完全开源的项目,采用 MIT 许可证发布,允许学术研究与商业应用自由使用。这一发布标志着小米在大模型领域迈出了关键一步,也为全球开发者提供了一个高性能、低成本、可商用的先进开源替代方案。














