











一款开源免费的 Spleeter 伴奏和人声分离工具



在数字音频处理领域,有一种日益流行的技术叫做“源分离”(Source Separation),它旨在从混合音频中分离出不同的音频成分,如伴奏和人声。这一技术不仅在音乐制作、音频后期处理,甚至在语音识别等领域都有着广泛的应用。
近年来,由 Deezer 公司开发的开源工具 Spleeter 因其卓越的性能和易用性而备受推崇。本文简鹿办公将深入探讨 S pleeter 如何实现伴奏和人声的分离,以及如何使用它来进行音频处理。

什么是 Spleeter?
Spleeter 是一款基于深度学习的音频源分离工具,它使用了先进的神经网络模型来分析和分割音频文件。与其他音频编辑软件不同,Spleeter 的核心优势在于它能够智能地区分和提取音频中的不同元素,特别擅长分离伴奏和人声,即便是在复杂的音频环境中也能表现出色。
Spleeter 的工作原理
Spleeter 采用了一种称为 U-Net 的卷积神经网络架构,该架构经过训练,能够识别和分离音频信号中的特定特征。在处理音频文件时,Spleeter 会将音频信号分解成频谱图,然后利用预训练的模型来分析每个频率成分,最终将它们分类为伴奏或人声。这个过程涉及了大量的计算,但得益于现代计算机硬件(尤其是 GPU)的高性能,Spleeter 能够在合理的时间内完成高质量的音频分离。
如何使用 Spleeter 分离伴奏和人声
使用 Spleeter 进行伴奏和人声的分离相对简单,但需要一些基本的软件安装和配置。以下是使用 Spleeter 的基本步骤:
1、首先,确保你的系统中安装了 Python(推荐版本3.6-3.7)、FFmpeg 以及必要的依赖库。
2、使用 pip 安装 Spleeter 库。如果网络不稳定,建议使用国内镜像源。
3、使用 Spleeter 提供的命令行接口,你可以通过以下命令来分离音频中的伴奏和人声:
spleeter separate -o /output/directory /input/audio/file.mp3
提示:这里,/output/directory 是你希望保存分离后音频的目录,/input/audio/file.mp3 是你希望分离的音频文件。
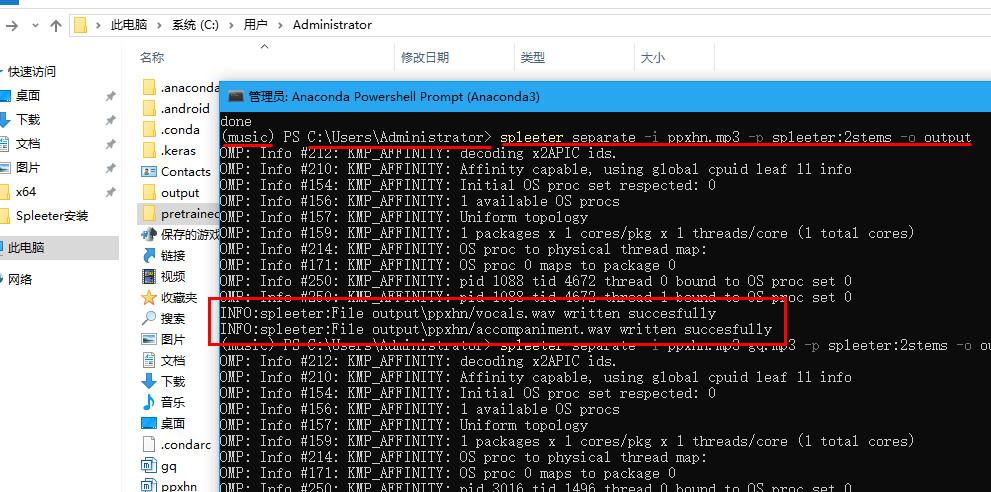
执行命令后,Spleeter 会在指定的输出目录下生成两个文件:accompaniment.wav(伴奏)和 vocals.wav(人声)。你可以使用音频播放器来检查分离的效果。
Spleeter 不仅为音乐制作人和音频工程师提供了一个强大的工具,使他们能够更精细地编辑和创作音乐,同时也为音频研究和开发开辟了新的可能性。通过利用深度学习的力量,Spleeter 展示了人工智能在音频处理领域的巨大潜力。无论是专业音频工作者还是音频处理爱好者,Spleeter 都值得探索和使用,以体验其在音乐分离方面的创新成果。
虽然 Spleeter 工具强大,但是对于一些需要批量处理的用户来说可能会在操作上有些不方便。不过你也可以通过简鹿人声分离工具轻松实现单个或批量音频人声及伴奏分离,有需要的朋友可以下载体验下。














